
Optimizing Distributed Training in Computing Power Networks: A Heterogeneity-aware Approach
DOI:
https://doi.org/10.64509/jicn.12.39Keywords:
Distributed training, synchronous communication mechanism, resource heterogeneity, computing power network, combinatorial optimizationAbstract
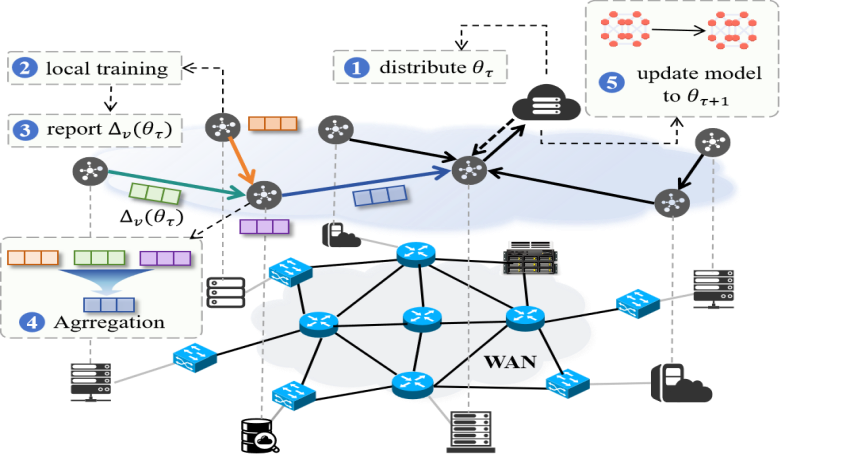
Distributed training over computing power network (CPN) suffers from high round-trip times (RTTs), volatile bandwidth, heterogeneous accelerators, and non-independent identically distributed (non‑IID) data, which collectively lead to imbalanced collaboration and slow convergence. To address these issues, we propose a heterogeneity-aware distributed training framework tailored for wide area network (WAN) settings. It adopts a hybrid hierarchical synchronization mechanism that redistributes communication load temporally and spatially, thus improving end-to-end training efficiency. In addition, we design a heuristic algorithm for optimizing the synchronization topology, guided by the computational capacities of training nodes and real-time network telemetry. We implement a distributed training system and validate the proposed framework through extensive simulations, demonstrating consistent performance gains across diverse heterogeneous settings.
Downloads
References
[1] Wang, S., Zheng, H., Wen, X., Shang, F.: Distributed high-performance computing methods for accelerating deep learning training. Journal of Knowledge Learning and Science Technology, 3(3), 108–126 (2024). https://doi.org/10.60087/jklst.v3.n3.p108-126 DOI: https://doi.org/10.60087/jklst.v3.n3.p108-126
[2] Sun, Y., Liu, J., Huang, H.-Y., Zhang, X., Lei, B., Peng, J., Wang, W.: Computing power network: A survey. China Communications, 21(9), 109–145 (2024). https://doi.org/10.23919/JCC.ja.2021-0776 DOI: https://doi.org/10.23919/JCC.ja.2021-0776
[3] Pei, J., Liu, W., Li, J., Wang, L., Liu, C.: A review of federated learning methods in heterogeneous scenarios. IEEE Transactions on Consumer Electronics, 70(3), 5983–5999 (2024). https://doi.org/10.1109/TCE.2024.3385440 DOI: https://doi.org/10.1109/TCE.2024.3385440
[4] Oughton, E.J., Lehr, W., Katsaros, K., Selinis, I., Bubley, D., Kusuma, J.: Revisiting wireless internet connectivity: 5G vs Wi-Fi 6. Telecommunications Policy, 45(5), 102127 (2021). https://doi.org/10.1016/j.telpol.2021.102127 DOI: https://doi.org/10.1016/j.telpol.2021.102127
[5] Gangidi, A., Miao, R., Zheng, S., Bondu, S.J., Goes, G., Morsy, H., Puri, R., Riftadi, M., Shetty, A.J., Yang, J., Shuqiang Zhang, S., et al.: RDMA over Ethernet for distributed training at Meta scale. In Proceedings of the ACM SIGCOMM 2024 Conference, pp. 57–70 (2024). https://doi.org/10.1145/3651890.3672233 DOI: https://doi.org/10.1145/3651890.3672233
[6] Zhang, Z., Cai, D., Zhang, Y., Xu, M., Wang, S., Zhou, A.: FedRDMA: Communication-efficient crosssilo federated LLM via chunked RDMA transmission. In Proceedings of the 4th Workshop on Machine Learning and Systems, pp. 126–133 (2024). https://doi.org/10.1145/3642970.3655834 DOI: https://doi.org/10.1145/3642970.3655834
[7] Alhafiz, F., Basuhail, A.: The data heterogeneity issue regarding COVID-19 lung imaging in federated learning: an experimental study. Big Data and Cognitive Computing, 9(1), 11 (2025). https://doi.org/10.3390/bdcc9010011 DOI: https://doi.org/10.3390/bdcc9010011
[8] Haddadpour, F., Kamani, M.M., Mahdavi, M., Cadambe, V.R.: Local SGD with periodic averaging: Tighter analysis and adaptive synchronization. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 11082–11094 (2019). https://doi.org/10.1145/3472456.3472508 DOI: https://doi.org/10.1145/3472456.3472508
[9] Tu, J., Yang, L., Cao, J.: Distributed Machine Learning in Edge Computing: Challenges, Solutions and Future Directions. ACM Computing Surveys, 57(5), 1–37 (2025). https://doi.org/10.1145/3708495 DOI: https://doi.org/10.1145/3708495
[10] Han, L., Huang, X., Li, D., Zhang, Y.: RingFFL: A ring-architecture-based fair federated learning framework. Future Internet, 15(2), 68 (2023). https://doi.org/10.3390/fi15020068 DOI: https://doi.org/10.3390/fi15020068
[11] Cho, M., Finkler, U., Kung, D.: BlueConnect: Novel hierarchical all-reduce on multi-tiered network for deep learning. In 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), PP. 1–8 (2019).
[12] Chai, Z., Ali, A., Zawad, S., Truex, S., Anwar, A., Baracaldo, N., Zhou, Y., Ludwig, H., Yan, F., Cheng, Y.: TiFL: A tier-based federated learning system. In Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing (HPDC), pp. 125–136 (2020). https://doi.org/10.1145/3369583.3392686 DOI: https://doi.org/10.1145/3369583.3392686
[13] Yuan, J., Xu, M., Ma, X., Zhou, A., Liu, X., Wang, S.: Hierarchical federated learning through LAN-WAN orchestration. arXiv preprint arXiv:2010.11612 (2020). https://doi.org/10.48550/arXiv.2010.11612
[14] Reisizadeh, A., Mokhtari, A., Hassani, H., Jadbabaie, A., Pedarsani, R.: FedPAQ: A communication-efficient federated learning method with periodic averaging and quantization. In International Conference on Artificial Intelligence and Statistics (AISTATS). Proceedings of Machine Learning Research (PMLR), pp. 2021–2031 (2020).
[15] Hosseinalipour, S., Azam, S.S., Brinton, C.G., Michelusi, N., Aggarwal, V., Love, D.J.: MultiStage Hybrid Federated Learning Over Large-Scale D2D-Enabled Fog Networks. IEEE/ACM Transactions on Networking, 30(4), 1569–1584 (2022). https://doi.org/10.1109/TNET.2022.3143495 DOI: https://doi.org/10.1109/TNET.2022.3143495
[16] Mayer, R., Jacobsen, H.A.: Scalable deep learning on distributed infrastructures: Challenges, techniques, and tools. ACM Computing Surveys (CSUR), 53(1), 1–37 (2020). https://doi.org/10.1145/3363554 DOI: https://doi.org/10.1145/3363554
[17] Ouyang, S., Dong, D., Xu, Y., Xiao, L.: Communication optimization strategies for distributed deep neural network training: A survey. Journal of Parallel and Distributed Computing, 149, 52–65 (2021). https://doi.org/10.1016/j.jpdc.2020.11.005 DOI: https://doi.org/10.1016/j.jpdc.2020.11.005
[18] Dutta, A., Bergou, E.H., Abdelmoniem, A.M., Ho, C.-Y., Sahu, A., Canini, M., Kalnis, P.: On the discrepancy between the theoretical analysis and practical implementations of compressed communication for distributed deep learning. In Proceedings of the AAAI Conference on Artificial Intelligence, pp. 3817–3824 (2020). https://doi.org/10.1609/aaai.v34i04.5793 DOI: https://doi.org/10.1609/aaai.v34i04.5793
[19] Duan, S., Wang, D., Ren, J., Lyn, F., Zhang, Y., Wu, H.: Distributed artificial intelligence empowered by end-edge-cloud computing: A survey. IEEE Communications Surveys & Tutorials, 25(1), 591–624 (2022). https://doi.org/10.1109/COMST.2022.3218527 DOI: https://doi.org/10.1109/COMST.2022.3218527
[20] Chen, Z., Liu, X., Li, M., Hu, Y., Mei, H., Xing, H.: RINA: Enhancing ring-AllReduce with in-network aggregation in distributed model training. In 2024 IEEE 32nd International Conference on Network Protocols (ICNP), pp. 1–12. IEEE (2024). https://doi.org/10.1109/ICNP61940.2024.10858570 DOI: https://doi.org/10.1109/ICNP61940.2024.10858570
[21] Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., Catanzaro, B.: Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053 (2019). https://doi.org/10.48550/arXiv.1909.08053
[22] Hashemi, S.H., Abdu Jyothi, S., Campbell, R.H.: TicTac: Accelerating distributed deep learning with communication scheduling. In Proceedings of the 2nd Machine Learning and Systems (MLSys) Conference, pp. 418–430 (2019).
[23] Jayarajan, A., Wei, J., Gibson, G., Fedorova, A., Pekhimenko, G.: Priority-based parameter propagation for distributed DNN training. In Proceedings of the 2nd Machine Learning and Systems (MLSys) Conference, pp. 132–145 (2019).
[24] Yan, G., Li, T., Huang, S.-L., Lan, T., Song, L.: AC-SGD: Adaptively Compressed SGD for Communication-Efficient Distributed Learning. IEEE Journal on Selected Areas in Communications, 40(9), 2678–2693 (2022). https://doi.org/10.1109/JSAC.2022.3192050 DOI: https://doi.org/10.1109/JSAC.2022.3192050
[25] Wang, S., Li, D., Geng, J., Gu, Y., Cheng, Y.: Impact of network topology on the performance of DML: Theoretical analysis and practical factors. In IEEE INFOCOM 2019-IEEE Conference on Computer Communications, pp. 1729–1737 (2019). https://doi.org/10.1109/INFOCOM.2019.8737595 DOI: https://doi.org/10.1109/INFOCOM.2019.8737595
[26] Liu, D., Zhu, G., Zhang, J., Huang, K.: Data-importance aware user scheduling for communication-efficient edge machine learning. IEEE Transactions on Cognitive Communications and Networking, 7(1), 265–278 (2020). https://doi.org/10.1109/TCCN.2020.2999606 DOI: https://doi.org/10.1109/TCCN.2020.2999606
[27] Wang, Z., Duan, Q., Xu, Y., Zhang, L.: An efficient bandwidth-adaptive gradient compression algorithm for distributed training of deep neural networks. Journal of Systems Architecture, 150, 103116 (2024). https://doi.org/10.1016/j.sysarc.2024.103116 DOI: https://doi.org/10.1016/j.sysarc.2024.103116
[28] Ruan, M., Yan, G., Xiao, Y., Song, L., Xu, W.: Adaptive top-K in SGD for communication-efficient distributed learning. In GLOBECOM 2023—2023 IEEE Global Communications Conference, pp. 5280–5285 (2023). https://doi.org/10.1109/GLOBECOM54140.2023.10437811 DOI: https://doi.org/10.1109/GLOBECOM54140.2023.10437811
[29] Liao, Y., Xu, Y., Xu, H., Yao, Z., Wang, L., Qiao, C.: Accelerating federated learning with data and model parallelism in edge computing. IEEE/ACM Transactions on Networking, 32(1), 904–918 (2024). https://doi.org/10.1109/TNET.2023.3299851 DOI: https://doi.org/10.1109/TNET.2023.3299851
[30] Ling, Z., Jiang, X., Tan, X., He, H., Zhu, S., Yang, J.: Joint dynamic data and model parallelism for distributed training of DNNs over heterogeneous infrastructure. IEEE Transactions on Parallel and Distributed Systems, 36(2), 150–167 (2024). https://doi.org/10.1109/TPDS.2024.3506588 DOI: https://doi.org/10.1109/TPDS.2024.3506588
[31] Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V.: Federated optimization in heterogeneous networks. In Proceedings of the 3rd Machine Learning and Systems Conference, pp. 429–450 (2020).
[32] Tang, Z., Hu, Z., Shi, S., Cheung, Y.-M., Jin, Y., Ren, Z., Chu, X.: Data resampling for federated learning with non-IID labels. In Proceedings of the International Workshop on Federated and Transfer Learning for Data Sparsity and Confidentiality (in conjunction with IJCAI), (2021).
[33] Li, T., Sanjabi, M., Beirami, A., Smith, V.: Fair resource allocation in federated learning. arXiv preprint arXiv:1905.10497 (2019). https://doi.org/10.48550/arXiv.1905.10497
[34] Sun, S., Zhang, Z., Pan, Q., Liu, M., Wang, Y., He, T.: Staleness-controlled asynchronous federated learning: Accuracy and efficiency tradeoff. IEEE Transactions on Mobile Computing, 23(12), 12621–12634 (2024). https://doi.org/10.1109/TMC.2024.3416216 DOI: https://doi.org/10.1109/TMC.2024.3416216
[35] Xie, C., Koyejo, S., Gupta, I.: Asynchronous federated optimization. arXiv preprint arXiv:1903.03934 (2019). https://doi.org/10.48550/arXiv.1903.03934
[36] Awan, A.A., Hamidouche, K., Venkatesh, A., Panda, D.K.: Efficient large message broadcast using NCCL and CUDA-aware MPI for deep learning. In Proceedings of the 23rd European MPI Users’ Group Meeting (EuroMPI ’16), pp. 15–22 (2016). https://doi.org/10.1145/2966884.2966912 DOI: https://doi.org/10.1145/2966884.2966912
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Authors

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite






