
Exploring Test-time Adaptive Object Detection in the Frequency Domain
DOI:
https://doi.org/10.64509/jicn.12.40Keywords:
Test-time adaptation, object detection, frequency learningAbstract
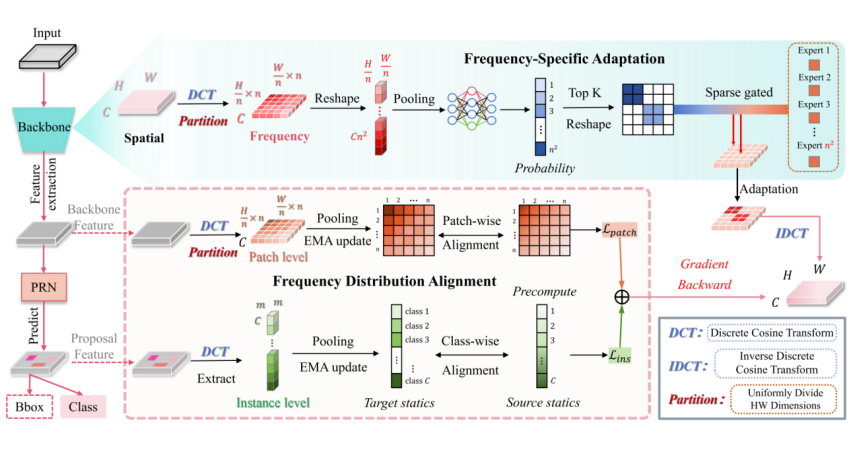
Continual test-time adaptive object detection (CTTA-OD) aims to online adapt a pre-trained detector to changing environments. Most CTTA-OD methods adapt the test domain shifts in the spatial domain, while overlooking the potential of the frequency cues. In this paper, we propose a novel frequency-specific adaptation framework that enables the detector rapidly adapt to the evolving target domain, enabling stable detection performance at test-time. Our motivation stems from the observation that distribution shifts caused by different perturbations primarily manifest in specific frequency bands. By selectively adapting only the affected bands, we reduce the optimization dimension, enabling rapid convergence to the new distribution. Specifically, we first decompose the spectrum into distinct bands by splitting it into patches, with each band handled by a specialized frequency adaptation expert. A learnable sparse gating network then selects the top-k affected frequency bands, assigning the corresponding experts to adapt each target domain. Moreover, we introduce a frequency alignment loss at both patch and instance levels, guiding the learning of the gating network and experts. Experiments on three benchmarks show that our method accelerates the CTTA-OD process within fewer batches, outperforming recent SOTA methods.
Downloads
References
[1] Zou, Z., Chen, K., Shi, Z., Guo, Y., Ye, J: Object detection in 20 years: A survey. Proceedings of the IEEE, 111(3), 257–276 (2023). https://doi.org/10.1109/JPROC.2023.3238524 DOI: https://doi.org/10.1109/JPROC.2023.3238524
[2] Zhao, Z., Zheng, P., Xu, S.T., Wu, X: Object detection with deep learning: A review. IEEE Transactions on Neural Networks and Learning Systems, 30(11), 3212–3232 (2019). https://doi.org/10.1109/TNNLS.2018.2876865 DOI: https://doi.org/10.1109/TNNLS.2018.2876865
[3] Cui, Y., Huang, S., Zhong, J., Liu, Z., Wang, Y., Sun, C., Li, B., Wang, X., Khajepour, A.: Drivellm: Charting the path toward full autonomous driving with large language models. IEEE Transactions on Intelligent Vehicles, 9(1), 1450–1464 (2023). https://doi.org/10.1109/TIV.2023.3327715 DOI: https://doi.org/10.1109/TIV.2023.3327715
[4] Zhang, J., Wang, K., Xu, R., Zhou, G., Hong, Y., Fang, X., Wu, Q., Zhang, Z., Wang, H.: Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852 (2024). https://doi.org/10.48550/arXiv.2402.15852 DOI: https://doi.org/10.15607/RSS.2024.XX.079
[5] Geiger, A., Lenz, P., Urtasun, R.: Towards online domain adaptive object detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 478–488 (2023). https://doi.org/10.1109/WACV56688.2023.00055 DOI: https://doi.org/10.1109/WACV56688.2023.00055
[6] Chen, Y., Xu, X., Su, Y., Jia, K.: Stfar: Improving object detection robustness at test-time by selftraining with feature alignment regularization. arXiv preprint arXiv:2303.17937 (2023). https://doi.org/10.48550/arXiv.2303.17937
[7] Mirza, M.J., Soneira, P.J., Lin, W., Kozinski, M., Possegger, H., Bischof, H.: ActMAD: Activation Matching to Align Distributions for Test-Time-Training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 24152–24161 (2023). https://doi.org/10.1109/CVPR52729.2023.02313 DOI: https://doi.org/10.1109/CVPR52729.2023.02313
[8] Yoo, J., Lee, D., Chung, I., Kim, D., Kwak, N.: What how and when should object detectors update in cotinually changing test domains? In Proceedings of the IEEE/CVF conference on computer vision and patternrecognition, pp. 23354–23363 (2024). https://doi.org/10.1109/CVPR52733.2024.02204 DOI: https://doi.org/10.1109/CVPR52733.2024.02204
[9] Hendrycks, D., Dietterich, T.: Benchmarking neural network robustness to common corruptions and perturbations. arXiv preprint arXiv:1903.12261 (2019). https://doi.org/10.48550/arXiv.1903.12261
[10] Sakaridis, C., Dai, D., Van Gool, L.: ACDC: The adverse conditions dataset with correspondences for semantic driving scene understanding. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 10765–10775 (2021). https://doi.org/10.1109/ICCV48922.2021.01059 DOI: https://doi.org/10.1109/ICCV48922.2021.01059
[11] Sun, T., Segu, M., Postels, J., Wang, Y., Van Gool, L., Schiele, B., Tombari, F., Yu, F.: SHIFT: A synthetic driving dataset for continuous multitask domain adaptation. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 21371–21382 (2022). https://doi.org/10.1109/CVPR52688.2022.02068 DOI: https://doi.org/10.1109/CVPR52688.2022.02068
[12] Bottou, L., Bousquet, O.: The tradeoffs of large scale learning. In Proceedings of the 21st International Conference on Neural Information Processing Systems, pp. 161–168 (2007)
[13] Ge, R., Huang, F., Jin, C., Yuan, Y.: Escaping from saddle points—online stochastic gradient for tensor decomposition. In Conference on learning theory, pp. 797–842 (2015).
[14] Nussbaumer, H.J.: The fast Fourier transform in Fast Fourier Transform and Convolution Algorithms, pp. 80-111, Springer, Berlin (1981). https://doi.org/10.1007/978-3-642-81897-4_4 DOI: https://doi.org/10.1007/978-3-662-00551-4_4
[15] Jiang, X., Zhang, X., Gao, N., Deng, Y.: When fast fourier transform meets transformer for image restoration. In European conference on computer vision, pp. 381–402 (2024). https://doi.org/10.1007/978-3-031-72995-9_22 DOI: https://doi.org/10.1007/978-3-031-72995-9_22
[16] Mirza, M.J., Micorek, J., Possegger, H., Bischof, H.: The norm must go on: Dynamic unsupervised domain adaptation by normalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14765–14775 (2022). https://doi.org/10.1109/CVPR52688.2022.01435 DOI: https://doi.org/10.1109/CVPR52688.2022.01435
[17] Cao, S., Zheng, J., Liu, Y., Zhao, B., Yuan, Z., Li, W., Dong, R., Fu, H.: Exploring test-time adaptation for object detection in continually changing environments. arXiv preprint arXiv:2406.16439 (2024). https://doi.org/10.48550/arXiv.2406.16439
[18] Sinha, S., Gehler, P., Locatello, F., Schiele, B.: Test: Test-time self-training under distribution shift. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 2759–2769 (2023). https://doi.org/10.1109/WACV56688.2023.00278 DOI: https://doi.org/10.1109/WACV56688.2023.00278
[19] Liu, Y., Wang, J., Huang, C., Wu, Y., Xu, Y., Cao, X.: MLFA: Towards realistic test time adaptive object detection by multi-level feature alignment. IEEE Transactions on Image Processing, 33, 5837–5848 (2024). https://doi.org/10.1109/TIP.2024.3473532 DOI: https://doi.org/10.1109/TIP.2024.3473532
[20] Pitas, I.: Digital image processing algorithms and applications. Wiley, New York (2000).
[21] Mevenkamp, N., Berkels, B.: Variational multi-phase segmentation using high-dimensional local features. In 2016 IEEE winter conference on applications of computer vision, pp. 1–9 (2016). https://doi.org/10.1109/WACV.2016.7477729 DOI: https://doi.org/10.1109/WACV.2016.7477729
[22] Chi, L., Jiang, B., Mu, Y.: Fast fourier convolution. In Advances in Neural Information Processing Systems 33 (NeurIPS 2020), pp. 1–10 (2020).
[23] Buchholz, T.O., Jug, F.: Fourier image transformer. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1846–1854 (2022). https://doi.org/10.1109/CVPRW56347.2022.00201 DOI: https://doi.org/10.1109/CVPRW56347.2022.00201
[24] Nguyen, T., Pham, M., Nguyen, T., Nguyen, K., Osher, S., Ho, N.: Fourierformer: Transformer meets generalized fourier integral theorem. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp. 29319–29335 (2020)
[25] Pratt, H., Williams, B., Coenen, F., Zheng, Y.: FCNN: Fourier convolutional neural networks. In Joint European conference on machine learning and knowledge discovery in databases, pp. 786–798 (2017). https://doi.org/10.1007/978-3-319-71249-9_47 DOI: https://doi.org/10.1007/978-3-319-71249-9_47
[26] Guibas, J., Mardani, M., Li, Z., Tao, A., Anandkumar, A., Catanzaro, B.: Adaptive fourier neural operators: Efficient token mixers for transformers. arXiv preprint arXiv:2111.13587 (2021). https://doi.org/10.48550/arXiv.2111.13587
[27] Huang, J., Guan, D., Xiao, A., Lu, S.: Fsdr: Frequency space domain randomization for domain generalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 6891–6902 (2021). https://doi.org/10.1109/CVPR46437.2021.00682 DOI: https://doi.org/10.1109/CVPR46437.2021.00682
[28] Liu, Q., Chen, C., Qin, J., Dou, Q., Heng, P. A.: FedDG: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1013–1023 (2021). https://doi.org/10.1109/CVPR46437.2021.00107 DOI: https://doi.org/10.1109/CVPR46437.2021.00107
[29] Xu, Q., Zhang, R., Zhang, Y., Wang, Y., Tian, Q.: A fourier-based framework for domain generalization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 14383–14392 (2021). https://doi.org/10.1109/CVPR46437.2021.01415 DOI: https://doi.org/10.1109/CVPR46437.2021.01415
[30] Yang, Y., Soatto, S.: FDA: Fourier domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4085–4095 (2020). https://doi.org/10.1109/CVPR42600.2020.00414 DOI: https://doi.org/10.1109/CVPR42600.2020.00414
[31] Wang, H., Wu, X., Huang, Z., Xing, E.P.: High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8684–8694 (2020). https://doi.org/10.1109/CVPR42600.2020.00871 DOI: https://doi.org/10.1109/CVPR42600.2020.00871
[32] Xu, Z.J.: Understanding training and generalization in deep learning by fourier analysis. arXiv preprint arXiv:1808.04295 (2018). https://doi.org/10.48550/arXiv.1808.04295
[33] Yin, D., Gontijo Lopes, R., Shlens, J., Cubuk, E.D., Gilmer, J.: A fourier perspective on model robustness in computer vision. In Proceedings of the 33rd International Conference on Neural Information Processing Systems , pp. 13276–13286 (2019).
[34] Fedus, W., Dean, J., Zoph, B.: A review of sparse expert models in deep learning. arXiv preprint arXiv:2209.01667 (2022). https://doi.org/10.48550/arXiv.2209.01667
[35] Jacobs, R.A., Jordan, M.I., Nowlan, S.J., Hinton, G.E.: Adaptive mixtures of local experts. Neural Computation, 3(1), 79–87 (1991). https://doi.org/10.1162/neco.1991.3.1.79 DOI: https://doi.org/10.1162/neco.1991.3.1.79
[36] Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., Chen, Z.: Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668 (2020). https://doi.org/10.48550/arXiv.2006.16668
[37] Aljundi, R., Chakravarty, P., Tuytelaars, T.: Expert gate: Lifelong learning with a network of experts. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3366–3375 (2017). https://doi.org/10.1109/CVPR.2017.753 DOI: https://doi.org/10.1109/CVPR.2017.753
[38] Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., Dean, J.: Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017). https://doi.org/10.48550/arXiv.1701.06538
[39] Eigen, D., Ranzato, M. A., Sutskever, I.: Learning factored representations in a deep mixture of experts. arXiv preprint arXiv:1312.4314 (2013). https://doi.org/10.48550/arXiv.1312.4314
[40] DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., et al.: Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434 (2024). https://doi.org/10.48550/arXiv.2405.04434
[41] Jiang, A.Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D.S., de las Casas, D., Hanna, E.B., Bressand, F., et al.: Mixtral of experts. arXiv preprint arXiv:2401.04088 (2024). https://doi.org/10.48550/arXiv.2401.04088
[42] Fedus, W., Zoph, B., Shazeer, N.: Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(1), 5232–5270, (2022). https://dl.acm.org/doi/abs/10.5555/3586589.3586709
[43] Ahmed, N., Natarajan, T., Rao, K.R.: Discrete cosine transform. IEEE Transactions on Computers, 100(1), 90–93 (2006). https://doi.org/10.1109/T-C.1974.223784 DOI: https://doi.org/10.1109/T-C.1974.223784
[44] Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149 (2016). https://doi.org/10.1109/TPAMI.2016.2577031 DOI: https://doi.org/10.1109/TPAMI.2016.2577031
[45] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3213–3223 (2016). https://doi.org/10.1109/CVPR.2016.350 DOI: https://doi.org/10.1109/CVPR.2016.350
[46] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778 (2016). https://doi.org/10.1109/CVPR.2016.90 DOI: https://doi.org/10.1109/CVPR.2016.90
[47] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255 (2009). https://doi.org/10.1109/CVPR.2009.5206848 DOI: https://doi.org/10.1109/CVPR.2009.5206848
[48] Wang, Q., Fink, O., Van Gool, L., Dai, D.: Continual test-time domain adaptation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 7201–7211 (2022). https://doi.org/10.1109/CVPR52688.2022.00706 DOI: https://doi.org/10.1109/CVPR52688.2022.00706
[49] Liu, J., Yang, S., Jia, P., Zhang, R., Lu, M., Guo, Y., Xue, W., Zhang, S: Vida: Homeostatic visual domain adapter for continual test time adaptation. arXiv preprint arXiv:2306.04344 (2023). https://doi.org/10.48550/arXiv.2306.04344
[50] Yan, C.W., Foo, S.Q., Trinh, V.H., Yeung, D.Y., Wong, K.H., Wong, W.K.: Fourier amplitude and correlation loss: Beyond using L2 loss for skillful precipitation nowcasting. In Proceedings of the 38th International Conference on Neural Information Processing Systems, pp. 100007–100041 (2024). DOI: https://doi.org/10.52202/079017-3173
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Authors

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite






