
GraphPilot: GUI Task Automation with One-Step LLM Reasoning Powered by Knowledge Graph
DOI:
https://doi.org/10.64509/jicn.21.45Keywords:
Mobile GUI Agents, Mobile Task Automation, Large Language Models, App AnalysisAbstract
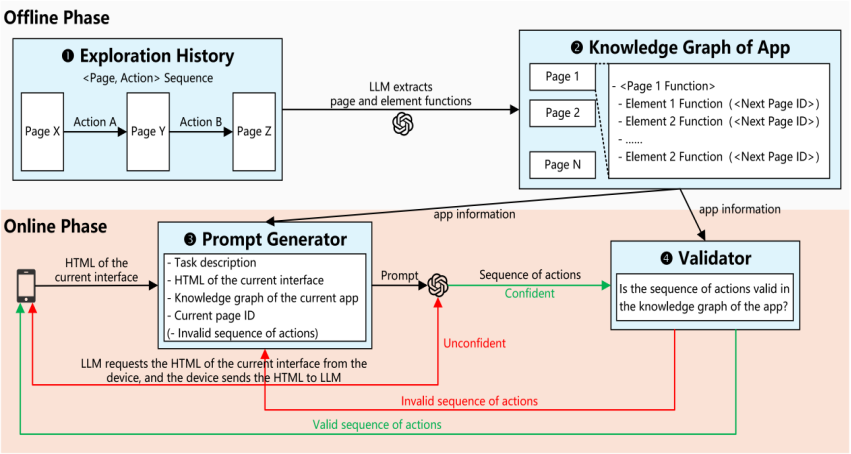
Mobile graphical user interface (GUI) agents are designed to automate everyday tasks on smartphones. Recent advances in large language models (LLMs) have significantly enhanced the capabilities of mobile GUI agents. However, most LLM-powered mobile GUI agents operate in stepwise query-act loops, which incur high latency due to repeated LLM queries. We present GraphPilot, a mobile GUI agent that leverages knowledge graphs of the target apps to complete user tasks in almost one LLM query. GraphPilot operates in two complementary phases to enable efficient and reliable LLM-powered GUI task automation. In the offline phase, it explores target apps, records and analyzes interaction history, and constructs an app-specific knowledge graph that encodes functions of pages and elements as well as transition rules for each app. In the online phase, given an app and a user task, it leverages the knowledge graph of the given app to guide the reasoning process of LLM. When the reasoning process encounters uncertainty, GraphPilot dynamically requests the HTML representation of the current interface to refine subsequent reasoning. Finally, a validator checks the generated sequence of actions against the transition rules in the knowledge graph, performing iterative corrections to ensure it is valid. The structured, informative information in the knowledge graph allows the LLM to plan the complete sequence of actions required to complete the user task. On the DroidTask benchmark, GraphPilot improves task completion rate over Mind2Web and AutoDroid, while substantially reducing latency and the number of LLM queries.
Downloads
References
[1] Liu, G., Zhao, P., Liang, Y., Liu, L., Guo, Y., Xiao, H., Lin, W., Chai, Y., Han, Y., Ren, S., et al.: LLM-Powered GUI Agents in Phone Automation: Surveying Progress and Prospects. Transactions on Machine Learning Research, 1–75 (2025) DOI: https://doi.org/10.20944/preprints202501.0413.v1
[2] Zhang, C., Yang, Z., Liu, J., Li, Y., Han, Y., Chen, X., Huang, Z., Fu, B., Yu, G.: AppAgent: Multimodal Agents as Smartphone Users. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pp. 1–20 (2025). https://doi.org/10.1145/3706598.3713600 DOI: https://doi.org/10.1145/3706598.3713600
[3] Wen, H., Li, Y., Liu, G., Zhao, S., Yu, T., Li, T.J.-J., Jiang, S., Liu, Y., Zhang, Y., Liu, Y.: AutoDroid: LLMpowered Task Automation in Android. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pp. 543–557 (2024). https://doi.org/10.1145/3636534.3649379 DOI: https://doi.org/10.1145/3636534.3649379
[4] Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2Web: Towards a generalist agent for the web. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 28091–28114 (2023)
[5] UI/Application Exerciser Monkey. https://developer.android.com/studio/test/other-testing-tools/monkey Access September 12, 2025
[6] SikuliX by RaiMan. http://www.sikulix.com Access September 12, 2025
[7] Wen, H., Wang, H., Liu, J., Li, Y.: DroidBotGPT: GPT-powered UI automation for Android. arXiv preprint arXiv:2304.07061 (2023). https://doi.org/10.48550/arXiv.2304.07061
[8] Baechler, G., Sunkara, S., Wang, M., Zubach, F., Mansoor, H., Etter, V., C˘arbune, V., Lin, J., Chen, J., Sharma, A.: ScreenAI: A vision-language model for UI and infographics understanding. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pp. 3045–3053 (2024). https://doi.org/10.24963/ijcai.2024/339 DOI: https://doi.org/10.24963/ijcai.2024/339
[9] Liu, Z., Li, C., Chen, C., Wang, J., Wu, B., Wang, Y., Hu, J., Wang, Q.: Vision-driven automated mobile GUI testing via multimodal large language model. arXiv preprint arXiv:2407.03037 (2024). https://doi.org/10.48550/arXiv.2407.03037
[10] Wu, Q., Gao, D., Lin, K.Q., Wu, Z., Guo, X., Li, P., Zhang, W., Wang, H., Shou, M.Z.: GUI action narrator: Where and when did that action take place? arXiv preprint arXiv:2406.13719 (2024). https://doi.org/10.48550/arXiv.2406.13719
[11] Huang, F., Jia, H., Sang, J., Shen, W., Wang, J., Xu, H., Yan, M., Zhang, J., Zhang, X.: Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration. In Advances in Neural Information Processing Systems 37, pp. 2686– 2710 (2024). https://doi.org/10.52202/079017-0088 DOI: https://doi.org/10.52202/079017-0088
[12] Wan, J., Song, S., Yu, W., Liu, Y., Cheng, W., Huang, F., Bai, X., Yao, C., Yang, Z.: OmniParser: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 15641–15653 (2024). https://doi.org/10.1109/cvpr52733.2024.01481 DOI: https://doi.org/10.1109/CVPR52733.2024.01481
[13] Lee, S., Choi, J., Lee, J., Wasi, M.H., Choi, H., Ko, S., Oh, S., Shin, I.: MobileGPT: Augmenting LLM with Human-like App Memory for Mobile Task Automation. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pp. 1119– 1133 (2024). https://doi.org/10.1145/3636534.3690682 DOI: https://doi.org/10.1145/3636534.3690682
[14] Jiang, W., Zhuang, Y., Song, C., Yang, X., Zhou, J.T., Zhang, C.: AppAgentX: Evolving GUI agents as proficient smartphone users. arXiv preprint arXiv:2503.02268 (2025). https://doi.org/10.48550/arXiv.2503.02268
[15] Verma, G., Kaur, R., Srishankar, N., Zeng, Z., Balch, T., Veloso, M.: AdaptAgent: Adapting Multimodal Web Agents with Few-Shot Learning from Human Demonstrations. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 20635–20651 (2025). https://doi.org/10.18653/v1/2025.acl-long.1008 DOI: https://doi.org/10.18653/v1/2025.acl-long.1008
[16] Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., et al.: CogAgent: A Visual Language Model for GUI Agents. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 14281–14290 (2024). https://doi.org/10.1109/cvpr52733.2024.01354 DOI: https://doi.org/10.1109/CVPR52733.2024.01354
[17] Zheng, B., Gou, B., Kil, J., Sun, H., Su, Y.: GPT4V(ision) is a generalist web agent, if grounded. In Proceedings of the 41st International Conference on Machine Learning, pp. 61349–61385 (2024)
[18] Song, Z., Li, Y., Fang, M., Li, Y., Chen, Z., Shi, Z., Huang, Y., Chen, X., Chen, L.: MMAC-Copilot: Multimodal Agent Collaboration Operating Copilot. arXiv preprint arXiv:2404.18074 (2024). https://doi.org/10.48550/arXiv.2404.18074
[19] Zhang, J., Zhao, C., Zhao, Y., Yu, Z., He, M., Fan, J.: MobileExperts: A dynamic tool-enabled agent team in mobile devices. arXiv preprint arXiv:2407.03913 (2024). https://doi.org/10.48550/arXiv.2407.03913
[20] Hoscilowicz, J., Janicki, A.: ClickAgent: Enhancing UI Location Capabilities of Autonomous Agents. In Proceedings of the 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pp. 471–476 (2025)
[21] Wang, Y., Zhang, H., Tian, J., Tang, Y.: Ponder & Press: Advancing Visual GUI Agent towards General Computer Control. In Findings of the Association for Computational Linguistics: ACL 2025, pp. 1461–1473 (2025). https://doi.org/10.18653/v1/2025.findings-acl.76 DOI: https://doi.org/10.18653/v1/2025.findings-acl.76
[22] Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: GPT-4o system card. arXiv preprint arXiv:2410.21276 (2024). https://doi.org/10.48550/arXiv.2410.21276
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Authors

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite






