
Language Models as 3D Layout Designers: a Survey
DOI:
https://doi.org/10.64509/jdi.11.51Keywords:
Layout Design, Large Language Model, LLM AgentAbstract
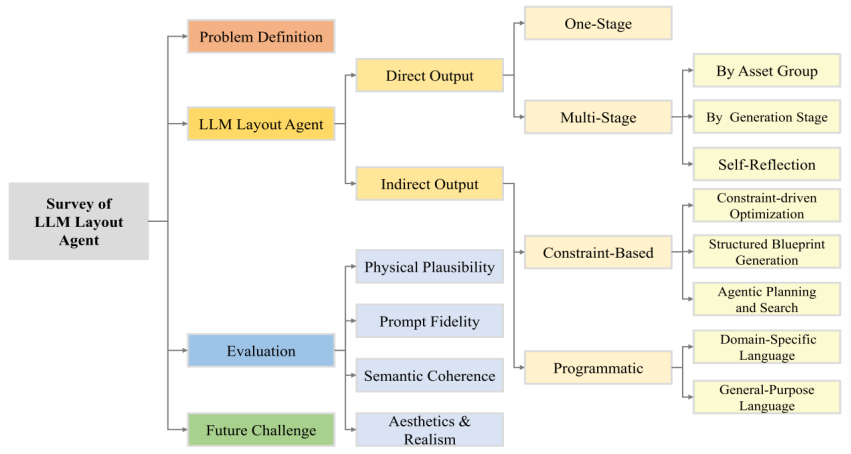
Scene design—spanning interior arrangement, virtual environment creation, and simulated asset generation for robotics—requires semantic understanding, physical plausibility, and aesthetic judgement. While traditional approaches rely on expert rules or optimization, Large Language Models (LLMs) promise more flexible, language-grounded reasoning and multimodal grounding. This survey provides a focused definition and task framework for layout agents and proposes a hierarchical categorization based on LLM layout agents' output representation. At the highest level, we distinguish Direct Methods, which predict asset poses (one-stage vs. multi-stage), from Indirect Methods, which emit intermediate representations (constraint-based or programmatic) that are converted to layouts via post-processing. Furthermore, we categorize the evaluation of layout agents into four dimensions: physical plausibility, prompt fidelity, semantic coherence, and aesthetics and realism, and summarize the commonly used evaluation methods. Finally, we review the current challenges faced by layout agents, including the lack of spatial reasoning ability, instability, poor generalization, and low efficiency. By organizing recent progress and identifying gaps, this survey aims to guide future research toward more capable, generalizable LLM layout agents.
Downloads
References
[1] Yu, L.-F., Yeung, S.-K., Tang, C.-K., Terzopoulos, D., Chan, T.F., Osher, S.J.: Make it home: automatic optimization of furniture arrangement. ACM Transactions on Graphics 30(4), 1–12 (2011) https://doi.org/10.1145/2010324.1964981
[2] Sun, X., Goel, D., Chang, A.X.: SemLayoutDiff: Semantic Layout Generation with Diffusion Model for Indoor Scene Synthesis. arXiv preprint arXiv:2508.18597 (2025) https://doi.org/10.48550/arXiv.2508.18597
[3] Raistrick, A., Mei, L., Kayan, K., Yan, D., Zuo, Y., Han, B., Wen, H., Parakh, M., Alexandropoulos, S., Lipson, L., Ma, Z., Deng, J.: Infinigen Indoors: Photorealistic Indoor Scenes using Procedural Generation. arXiv preprint arXiv:2406.11824 (2024) https://doi.org/10.48550/arXiv.2406.11824
[4] Peddiraju, P., Clark, C.: Procedural Image Generation Using Markov Wave Function Collapse in Advances in Artificial Intelligence and Applied Cognitive Computing, pp. 525–542. Springer, Cham, Switzerland (2021). https://doi.org/10.1007/978-3-030-70296-0_39
[5] Zhong, W., Cao, P., Jin, Y., Luo, L., Cai, W., Lin, J., Wang, H., Lyu, Z., Wang, T., Dai, B., Xu, X., Pang, J.: InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts. arXiv preprint arXiv:2509.10813 (2025) https://doi.org/10.48550/arXiv.2509.10813
[6] Alexander, C.: A pattern language: towns, buildings, construction. Oxford university press, Berkeley, California, USA (1977)
[7] Gschwandtner, M., Kwitt, R., Uhl, A., Pree, W.: BlenSor: Blender sensor simulation toolbox. In International Symposium on Visual Computing, pp. 199–208 (2011). https://doi.org/10.1007/978-3-642-24031-7_20
[8] Parish, Y.I., M¨uller, P.: Procedural modeling of cities. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, pp. 301–308 (2001). https://doi.org/10.1145/383259.383292
[9] Merrell, P., Schkufza, E., Li, Z., Agrawala, M., Koltun, V.: Interactive furniture layout using interior design guidelines. In ACM SIGGRAPH 2011 Papers, pp. 49–86 (2011). https://doi.org/10.1145/1964921.1964982
[10] Li, Y., Chen, H., Yu, P., Yang, L.: A review of artificial intelligence in enhancing architectural design efficiency. Applied Sciences 15(3), 1476 (2025) https://doi.org/10.3390/app15031476
[11] Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022) https://doi.org/10.48550/arXiv.2209.14988
[12] Paschalidou, D., Kar, A., Shugrina, M., Kreis, K., Geiger, A., Fidler, S.: Atiss: Autoregressive transformers for indoor scene synthesis. In Advances in Neural Information Processing Systems 34, NeurIPS 2021, pp. 12013–12026 (2021)
[13] Li, M., Patil, A.G., Xu, K., Chaudhuri, S., Khan, O., Shamir, A., Tu, C., Chen, B., Cohen-Or, D., Zhang, H.: Grains: Generative recursive autoencoders for indoor scenes. ACM Transactions on Graphics 38(2), 1–16 (2019) https://doi.org/10.1145/3303766
[14] Wen, B., Xie, H., Chen, Z., Hong, F., Liu, Z.: 3D Scene Generation: A Survey. arXiv preprint arXiv:2505.05474 (2025) https://doi.org/10.48550/arXiv.2505.05474
[15] Wu, J., Zhang, C., Xue, T., Freeman, W.T., Tenenbaum, J.B.: Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Proceedings of the 30th International Conference on Neural Information Processing Systems, pp. 82–90 (2016)
[16] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99–106 (2021) https://doi.org/10.1145/3503250
[17] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695 (2022). https://doi.org/10.1109/CVPR52688.2022.01042
[18] Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., et al.: Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177 (2024) https://doi.org/10.48550/arXiv.2402.17177
[19] Fime, A.A., Mahmud, S., Das, A., Islam, M.S., Kim, J.-H.: Automatic Scene Generation: State-of-the-Art Techniques, Models, Datasets, Challenges, and Future Prospects. arXiv preprint arXiv:2410.01816 (2024) https://doi.org/10.48550/arXiv.2410.01816
[20] Zha, J., Fan, Y., Yang, X., Gao, C., Chen, X.: How to Enable LLM with 3D Capacity? A Survey of Spatial Reasoning in LLM. arXiv preprint arXiv:2504.05786 (2025) https://doi.org/10.48550/arXiv.2504.05786
[21] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6000–6010 (2017)
[22] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, pp. 1877–1901 (2020)
[23] Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. In Proceedings of the 3rd International Conference on Computer, Artificial Intelligence and Control Engineering, pp. 405–409 (2024). https://doi.org/10.1145/3672758.3672824
[24] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) https://doi.org/10.48550/arXiv.2303.08774
[25] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) https://doi.org/10.48550/arXiv.2302.13971
[26] Feng, W., Zhu, W., Fu, T.-j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: Compositional visual planning and generation with large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 18225–18250 (2023)
[27] Zhang, J., Huang, J., Jin, S., Lu, S.: Visionlanguage models for vision tasks: A survey. IEEE transactions on pattern analysis and machine intelligence 46(8), 5625–5644 (2024) https://doi.org/10.1109/TPAMI.2024.3369699
[28] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 34892–34916 (2023)
[29] Hu, Z., Iscen, A., Jain, A., Kipf, T., Yue, Y., Ross, D.A., Schmid, C., Fathi, A.: Scenecraft: An llm agent for synthesizing 3d scenes as blender code. In Proceedings of the 41st International Conference on Machine Learning, pp. 19252–19282 (2024)
[30] Liu, X., Tai, Y.-W., Tang, C.-K.: Agentic 3D Scene Generation with Spatially Contextualized VLMs. arXiv preprint arXiv:2505.20129 (2025) https://doi.org/10.48550/arXiv.2505.20129
[31] Xia, X., Zhang, D., Liao, Z., Hou, Z., Sun, T., Li, J., Fu, L., Dong, Y.: SceneGenAgent: Precise Industrial Scene Generation with Coding Agent. arXiv preprint arXiv:2410.21909 (2025) https://doi.org/10.48550/arXiv.2410.21909
[32] Shi, Z., Peng, S., Xu, Y., Geiger, A., Liao, Y., Shen, Y.: Deep generative models on 3d representations: A survey. arXiv preprint arXiv:2210.15663 (2022) https://doi.org/10.48550/arXiv.2210.15663
[33] Sun, F.-Y., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., Wu, J.: Layoutvlm: Differentiable optimization of 3d layout via vision-language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 29469–29478 (2025). https://doi.org/10.1109/CVPR52734.2025.02744
[34] Tang, J., Nie, Y., Markhasin, L., Dai, A., Thies, J., Nießner, M.: Diffuscene: Denoising diffusion models for generative indoor scene synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20507–20518 (2024). https://doi.org/10.1109/CVPR52733.2024.01938
[35] Kerbl, B., Kopanas, G., Leimk¨uhler, T., Drettakis, G.: 3D Gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4), 1–14 (2023) https://doi.org/10.1145/3592433
[36] Tancik, M., Casser, V., Yan, X., Pradhan, S., Mildenhall, B., Srinivasan, P.P., Barron, J.T., Kretzschmar, H.: Block-nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8248–8258 (2022). https://doi.org/10.1109/CVPR52688.2022.00807
[37] M¨uller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM transactions on graphics 41(4), 1–15 (2022) https://doi.org/10.1145/3528223.3530127
[38] Lin, C.H., Lee, H.-Y., Menapace, W., Chai, M., Siarohin, A., Yang, M.-H., Tulyakov, S.: Infinicity: Infinite-scale city synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22808–22818 (2023). https://doi.org/10.1109/ICCV51070.2023.02085
[39] Bian, Z., Ren, R., Yang, Y., Callison-Burch, C.: HOLODECK 2.0: Vision-Language-Guided 3D World Generation with Editing. arXiv preprint arXiv:2508.05899 (2025) https://doi.org/10.48550/arXiv.2508.05899
[40] Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In SIGGRAPH Asia 2024 Conference Papers, pp. 1–11 (2024). https://doi.org/10.1145/3680528.3687614
[41] Xing, Z., Feng, Q., Chen, H., Dai, Q., Hu, H., Xu, H., Wu, Z., Jiang, Y.-G.: A survey on video diffusion models. ACM Computing Surveys 57(2), 1–42 (2024) https://doi.org/10.1145/3696415
[42] Liu, H., Yan, W., Zaharia, M., Abbeel, P.: World model on million-length video and language with blockwise ringattention. arXiv preprint arXiv:2402.08268 (2024) https://doi.org/10.48550/arXiv.2402.08268
[43] Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) https://doi.org/10.48550/arXiv.2309.16609
[44] Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024) https://doi.org/10.48550/arXiv.2412.19437
[45] Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improving language understanding by generative pre-training. https://s3-us-west-2. amazonaws.com/openai-assets/research-covers/ language-unsupervised/language understanding paper.pdf Accessed 2025-11-28
[46] Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35 (NeurIPS 2022), pp. 27730–27744 (2022)
[47] Alayrac, J.-B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems 35, 23716–23736 (2022)
[48] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748–8763 (2021)
[49] Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International Conference on Machine Learning, pp. 19730–19742 (2023)
[50] Wang, Z., Yu, J., Yu, A.W., Dai, Z., Tsvetkov, Y., Cao, Y.: Simvlm: Simple visual language model pretraining with weak supervision. arXiv preprint arXiv:2108.10904 (2021) https://doi.org/10.48550/arXiv.2108.10904
[51] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp. 24824– 24837 (2022)
[52] Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3D-LLM: Injecting the 3d world into large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 20482–20494 (2023)
[53] Wang, J., Jiang, H., Liu, Y., Ma, C., Zhang, X., Pan, Y., Liu, M., Gu, P., Xia, S., Li, W., et al.: A comprehensive review of multimodal large language models: Performance and challenges across different tasks. arXiv preprint arXiv:2408.01319 (2024) https://doi.org/10.48550/arXiv.2408.01319
[54] Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Wahid, A., Tompson, J., Vuong, Q., Yu, T., Huang, W., et al.: PalM-E: An embodied multimodal language model. In Proceedings of the 40th International Conference on Machine Learning, pp. 8469–8488 (2023)
[55] Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895 (2024) https://doi.org/10.48550/arXiv.2407.07895
[56] Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Proceedings of The 7th Conference on Robot Learning, pp. 2165–2183 (2023)
[57] Qi, Z., Fang, Y., Sun, Z., Wu, X., Wu, T., Wang, J., Lin, D., Zhao, H.: Gpt4point: A unified framework for point-language understanding and generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26417– 26427 (2024). https://doi.org/10.1109/CVPR52733.2024.02495
[58] Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., et al.: A survey on large language model based autonomous agents. Frontiers of Computer Science 18(6), 186345 (2024) https://doi.org/10.1007/s11704-024-40231-1
[59] Park, J.S., O’Brien, J., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pp. 1–22 (2023). https://doi.org/10.1145/3586183.3606763
[60] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, pp. 1–33 (2022)
[61] Schick, T., Dwivedi-Yu, J., Dess`ı, R., Raileanu, R., Lomeli, M., Hambro, E., Zettlemoyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 68539–68551 (2023)
[62] Zhou, Y., He, Z., Li, Q., Wang, C.: LAYOUTDREAMER: Physics-guided Layout for Text-to-3D Compositional Scene Generation. arXiv preprint arXiv:2502.01949 (2025) https://doi.org/10.48550/arXiv.2502.01949
[63] Rivera, C., Byrd, G., Paul, W., Feldman, T., Booker, M., Holmes, E., Handelman, D., Kemp, B., Badger, A., Schmidt, A., et al.: Conceptagent: Llmdriven precondition grounding and tree search for robust task planning and execution. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 8988–8995 (2025). https://doi.org/10.1109/ICRA55743.2025.11128414
[64] Yang, Y., Lu, J., Zhao, Z., Luo, Z., Yu, J.J.Q., Sanchez, V., Zheng, F.: LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model. arXiv preprint arXiv:2406.03866 (2024) https://doi.org/10.48550/arXiv.2406.03866
[65] Deng, J., Chai, W., Huang, J., Zhao, Z., Huang, Q., Gao, M., Guo, J., Hao, S., Hu, W., Hwang, J.-N., et al.: Citycraft: A real crafter for 3d city generation. arXiv preprint arXiv:2406.04983 (2024) https://doi.org/10.48550/arXiv.2406.04983
[66] Wang, J., Cao, N., Ding, Y., Xie, M., Gu, F., Chen, C.: SKE-Layout: Spatial Knowledge Enhanced Layout Generation with LLMs. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 19414–19423 (2025). https://doi.org/10.1109/CVPR52734.2025.01808
[68] Jiang, B., Ma, R.: Cot2Scene: Generating 3D Indoor Scenes Using CoT-Enhanced LLMs. In 2025 6th International Conference on Computer Engineering and Application (ICCEA), pp. 1687–1690 (2025). https://doi.org/10.1109/ICCEA65460.2025.11103192
[69] ¨Ocal, B.M., Tatarchenko, M., Karaoglu, S., Gevers, T.: SceneTeller: Language-to-3D Scene Generation. arXiv preprint arXiv:2407.20727 (2024) https://doi.org/10.48550/arXiv.2407.20727
[70] Zhou, X., Ran, X., Xiong, Y., He, J., Lin, Z., Wang, Y., Sun, D., Yang, M.-H.: GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting. arXiv preprint arXiv:2402.07207 (2024) https://doi.org/10.48550/arXiv.2402.07207
[71] Yang, Y., Sun, F.-Y., Weihs, L., VanderBilt, E., Herrasti, A., Han, W., Wu, J., Haber, N., Krishna, R., Liu, L., et al.: Holodeck: Language guided generation of 3d embodied ai environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16227–16237 (2024). https://doi.org/10.1109/CVPR52733.2024.01536
[72] Zeng, P., Gao, W., Li, J., Yin, J., Chen, J., Lu, S.: Automated residential layout generation and editing using natural language and images. Automation in Construction 174, 106133 (2025) https://doi.org/10.1016/j.autcon.2025.106133
[73] Gan, Z., Li, M., Chen, R., Ji, Z., Guo, S., Hu, H., Ye, G., Hu, Z.: StageDesigner: Artistic Stage Generation for Scenography via Theater Scripts. arXiv preprint arXiv:2503.02595 (2025) https://doi.org/10.48550/arXiv.2503.02595
[74] Ran, X., Li, Y., Xu, L., Yu, M., Dai, B.: Direct Numerical Layout Generation for 3D Indoor Scene Synthesis via Spatial Reasoning. arXiv preprint arXiv:2506.05341 (2025) https://doi.org/10.48550/arXiv.2506.05341
[75] Liu, J.-H., Zhang, S.-K., Zhang, C., Zhang, S.-H.: Controllable procedural generation of landscapes. In Proceedings of the 32nd ACM International Conference on Multimedia, pp. 6394–6403 (2024). https://doi.org/10.1145/3664647.3681129
[76] Yang, Y., Jia, B., Zhang, S., Huang, S.: SceneWeaver: All-in-One 3D Scene Synthesis with an Extensible and Self-Reflective Agent. arXiv preprint arXiv:2509.20414 (2025) https://doi.org/10.48550/arXiv.2509.20414
[77] Gao, J., Zhou, D., Liang, M., Liu, L., Fu, C.-W., Hu, X., Heng, P.-A.: DisCo-Layout: Disentangling and Coordinating Semantic and Physical Refinement in a Multi-Agent Framework for 3D Indoor Layout Synthesis. arXiv preprint arXiv:2510.02178 (2025) https://doi.org/10.48550/arXiv.2510.02178
[78] Fisher, M., Ritchie, D., Savva, M., Funkhouser, T., Hanrahan, P.: Example-based synthesis of 3D object arrangements. ACM Transactions on Graphics 31(6), 1–11 (2012) https://doi.org/10.1145/2366145.2366154
[79] Littlefair, G., Dutt, N.S., Mitra, N.J.: FlairGPT: Repurposing LLMs for interior designs. Computer Graphics Forum 44(2), 70036 (2025) https://doi.org/10.1111/cgf.70036
[80] Sun, W., Li, X., Li, M., Xu, K., Meng, X., Meng, L.: Hierarchically-Structured Open-Vocabulary Indoor Scene Synthesis with Pre-trained Large Language Model. In Proceedings of the AAAI Conference on Artificial Intelligence, pp. 7122–7130 (2025). https://doi.org/10.1609/aaai.v39i7.32765
[81] C¸ elen, A., Han, G., Schindler, K., Van Gool, L., Armeni, I., Obukhov, A., Wang, X.: I-design: Personalized llm interior designer, pp. 217–234 (2024). https://doi.org/10.1007/978-3-031-92387-6_17
[82] Zhou, M., Wang, X., Wang, Y., Zhang, Z.: RoomCraft: Controllable and Complete 3D Indoor Scene Generation. arXiv preprint arXiv:2506.22291 (2025) https://doi.org/10.48550/arXiv.2506.22291
[83] Fu, R., Wen, Z., Liu, Z., Sridhar, S.: AnyHome: OpenVocabulary Generation of Structured and Textured 3D Homes (2024). https://doi.org/10.48550/arXiv.2312.06644
[84] Liu, L., Chen, S., Jia, S., Shi, J., Jiang, Z., Jin, C., Zongkai, W., Hwang, J.-N., Li, L.: Graph Canvas for Controllable 3D Scene Generation. arXiv preprint arXiv:2412.00091 (2024) https://doi.org/10.48550/arXiv.2412.00091
[85] Gao, G., Liu, W., Chen, A., Geiger, A., Sch¨olkopf, B.: Graphdreamer: Compositional 3d scene synthesis from scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21295–21304 (2024). https://doi.org/10.1109/CVPR52733.2024.02012
[86] Wei, Y., Min, M.R., Vosselman, G., Li, L.E., Yang, M.Y.: Planner3D: LLM-enhanced graph prior meets 3D indoor scene explicit regularization. arXiv preprint arXiv:2403.12848 (2024) https://doi.org/10.48550/arXiv.2403.12848
[87] Li, X.-L., Li, H., Chen, H.-X., Mu, T.-J., Hu, S.-M.: DIScene: Object Decoupling and Interaction Modeling for Complex Scene Generation. In SIGGRAPH Asia 2024 Conference Papers, pp. 1–12 (2024). https://doi.org/10.1145/3680528.3687589
[88] Zhang, G., Wang, Y., Luo, C., Xu, S., Ming, Y., Peng, J., Zhang, M.: Visual Harmony: LLM’s Power in Crafting Coherent Indoor Scenes from Images. In Lin, Z., Cheng, M.-M., He, R., Ubul, K., Silamu, W., Zha, H., Zhou, J., Liu, C.-L. (eds.) Pattern Recognition and Computer Vision, pp. 3–17. Springer, Singapore (2025)
[89] Fu, R., Liu, J., Chen, X., Nie, Y., Xiong, W.: Scene-LLM: Extending Language Model for 3D Visual Understanding and Reasoning. arXiv preprint arXiv:2403.11401 (2024) https://doi.org/10.48550/arXiv.2403.11401
[90] Deng, W., Qi, M., Ma, H.: Global-local tree search in vlms for 3D indoor scene generation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 8975–8984 (2025). https://doi.org/10.1109/CVPR52734.2025.00839
[91] Chen, W., Chi, D., Liu, Y., Yang, Y., Zhang, Y., Zhuang, Y., Quan, X., Hao, J., Li, G., Lin, L.: AutoLayout: Closed-Loop Layout Synthesis via Slow-Fast Collaborative Reasoning. arXiv preprint arXiv:2507.04293 (2025) https://doi.org/10.48550/arXiv.2507.04293
[92] Ling, L., Lin, C.-H., Lin, T.-Y., Ding, Y., Zeng, Y., Sheng, Y., Ge, Y., Liu, M.-Y., Bera, A., Li, Z.: Scenethesis: A Language and Vision Agentic Framework for 3D Scene Generation. arXiv preprint arXiv:2505.02836 (2025) https://doi.org/10.48550/arXiv.2505.02836
[93] Liu, X., Tang, C.-K., Tai, Y.-W.: WorldCraft: PhotoRealistic 3D World Creation and Customization via LLM Agents. arXiv preprint arXiv:2502.15601 (2025) https://doi.org/10.48550/arXiv.2502.15601
[94] Zhang, Y., Li, Z., Zhou, M., Wu, S., Wu, J.: The scene language: Representing scenes with programs, words, and embeddings. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 24625–24634 (2025). https://doi.org/10.1109/CVPR52734.2025.0229
[95] Tam, H.I.I., Pun, H.I.D., Wang, A.T., Chang, A.X., Savva, M.: SceneMotifCoder: Example-driven Visual Program Learning for Generating 3D Object Arrangements. arXiv preprint arXiv:2408.02211 (2025) https://doi.org/10.48550/arXiv.2408.02211
[96] Gumin, M., Han, D.H., Yoo, S.J., Ganeshan, A., Jones, R.K., Aguina-Kang, R., Morris, S., Ritchie, D.: Imperative vs. Declarative Programming Paradigms for Open-Universe Scene Generation. arXiv preprint arXiv:2504.05482 (2025) https://doi.org/10.48550/arXiv.2504.05482
[97] Sun, C., Han, J., Deng, W., Wang, X., Qin, Z., Gould, S.: 3D-gpt: Procedural 3D modeling with large language models. In 2025 International Conference on 3D Vision (3DV), pp. 1253–1263 (2025). https://doi.org/10.1109/3DV66043.2025.00119
[98] Wang, C., Zhong, H., Chai, M., He, M., Chen, D., Liao, J.: Chat2Layout: Interactive 3D furniture layout with a multimodal LLM. arXiv preprint arXiv:2407.21333 (2024) https://doi.org/10.48550/arXiv.2407.21333
[99] Rezatofighi, H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I., Savarese, S.: Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 658–666 (2019). https://doi.org/10.1109/CVPR.2019.00075
[100] Tam, H.I.I., Pun, H.I.D., Wang, A.T., Chang, A.X., Savva, M.: SceneEval: Evaluating semantic coherence in text-conditioned 3D indoor scene synthesis. arXiv preprint arXiv:2503.14756 (2025) https://doi.org/10.48550/arXiv.2503.14756
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Authors

This work is licensed under a Creative Commons Attribution 4.0 International License.


