
Comprehensive Fashion Understanding from Images through Multimodal LLMs
DOI:
https://doi.org/10.64509/jdi.12.54Keywords:
Clothing Recognition, Fine-Grained Classification, Multi-Modal Large language Model, Clothing RetrievalAbstract
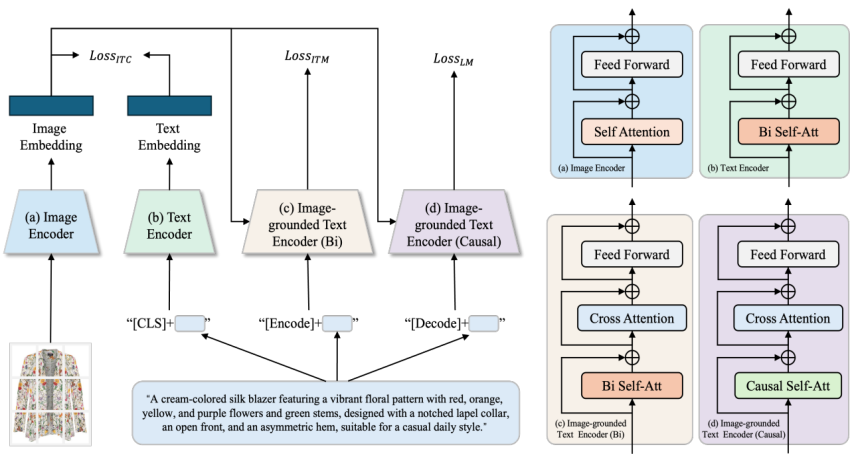
With the popularity of social media platforms in the information era, people are sharing a large volume of digital content online, including photos and other media data. The availability of media data over the Internet makes it very attractive to mine useful information from these data. However, for fashion image recognition, most existing datasets and methods are limited to coarse-grained categories or a small subset of attributes, lacking a comprehensive dataset and a holistic understanding of clothing. In this paper, we construct a fashion dataset with structured and comprehensive clothing descriptions using an MLLM (Multimodal Large Language Model) grounded in fashion knowledge. To ensure accurate understanding by the MLLM, we define a fashion schema and propose a schema-guided prompting strategy. Leveraging this dataset, we train a model based on BLIP (Bootstrapping Language-Image Pre-training) to recognize category information and fine-grained attributes of clothing images, and to learn text–image aligned representations for clothing image retrieval. Experimental results demonstrate that our approach significantly improves both attribute recognition and cross-modal retrieval performance compared to existing baselines.
Downloads
References
[1] Wang, X., Zhang, T., Tretter, D.R., Lin, Q.: Personal clothing retrieval on photo collections by color and attributes. IEEE transactions on multimedia 15(8), 2035-2045 (2013). https://doi.org/10.1109/TMM.2013.2279658
[2] Liu, S., Song, Z., Wang, M., Xu, C., Lu, H., Yan, S.: Street-to-shop: Cross-scenario clothing retrieval via parts alignment and auxiliary set. In Proceedings of the 20th ACM International Conference on Multimedia, pp. 1335-1336 (2012). https://doi.org/10.1109/CVPR.2012.6248071
[3] Chen, Q., Huang, J., Feris, R., Brown, L.M., Dong, J., Yan, S.: Deep domain adaptation for describing people based on fine-grained clothing attributes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5315-5324 (2015). https://doi.org/10.1109/CVPR.2015.7299169
[4] Huang, J., Feris, R.S., Chen, Q., Yan, S.: Cross-domain image retrieval with a dual attribute-aware ranking network. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1062-1070 (2015). https://doi.org/10.1109/ICCV.2015.127
[5] Liu, Z., Luo, P., Qiu, S., Wang, X., Tang, X.: Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1096-1104 (2016). https://doi.org/10.1109/CVPR.2016.124
[6] Dong, Q., Gong, S., Zhu, X.: Multi-task curriculum transfer deep learning of clothing attributes. In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 520-529 (2017). https://doi.org/10.1109/WACV.2017.64
[7] Ge, Y., Zhang, R., Wang, X., Tang, X., Luo, P.: Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5337-5345 (2019). https://doi.org/10.1109/CVPR.2019.00548
[8] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770-778 (2016). https://doi.org/10.1109/CVPR.2016.90
[9] Zou, X., Kong, X., Wong, W., Wang, C., Liu, Y., Cao, Y.: Fashionai: A hierarchical dataset for fashion understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp. 0-0 (2019). https://doi.org/10.1109/CVPRW.2019.00039
[10] Rostamzadeh, N., Hosseini, S., Boquet, T., Stokowiec, W., Zhang, Y., Jauvin, C., Pal, C.: Fashion-gen: The generative fashion dataset and challenge. arXiv preprint arXiv:1806.08317 (2018). https://doi.org/10.48550/arXiv.1806.08317
[11] Chen, Q., Li, J., Lu, G., Bi, X., Wang, B.: Clothing retrieval based on image bundled features. In 2012 IEEE 2nd International Conference on Cloud Computing and Intelligence Systems, pp. 980-984 (2012). https://doi.org/10.1109/CCIS.2012.6664323
[12] Abdulnabi, A.H., Wang, G., Lu, J., Jia, K.: Multi-task CNN model for attribute prediction. IEEE Transactions on Multimedia 17(11), 1949-1959 (2015). https://doi.org/10.1109/TMM.2015.2477680
[13] Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE transactions on pattern analysis and machine intelligence 39(6), 1137-1149 (2016). https://doi.org/10.1109/TPAMI.2016.2577031
[14] Sun, G.-L., Wu, X., Chen, H.-H., Peng, Q.: Clothing style recognition using fashion attribute detection. In Proceedings of the 8th International Conference on Mobile Multimedia Communications, pp. 145-148 (2015). https://doi.org/10.5555/2826112.2826142
[15] Lowe, D.G.: Distinctive image features from scale-invariant keypoints. International journal of computer vision 60(2), 91-110 (2004). https://doi.org/10.1023/B:VISI.0000029664.99615.94
[16] Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), pp. 886-893 (2005). https://doi.org/10.1109/CVPR.2005.177
[17] Liaw, A., Wiener, M.: Classification and regression by randomForest. R news 2(3), 18-22 (2002)
[18] Zhang, N., Donahue, J., Girshick, R., Darrell, T.: Part-based R-CNNs for fine-grained category detection. In European Conference on Computer Vision, pp. 834-849 (2014). https://doi.org/10.1007/978-3-319-10590-1_54
[19] Lin, D., Shen, X., Lu, C., Jia, J.: Deep lac: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1666-1674 (2015). https://doi.org/10.1109/CVPR.2015.7298775
[20] Huang, S., Xu, Z., Tao, D., Zhang, Y.: Part-stacked CNN for fine-grained visual categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1173-1182 (2016). https://doi.org/10.1109/CVPR.2016.132
[21] Wei, X.-S., Xie, C.-W., Wu, J., Shen, C.: Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognition 76, 704-714 (2018). https://doi.org/10.1016/j.patcog.2017.10.002
[22] Zhou, Y., Li, R., Zhou, Y., Mok, P.Y.: Describing clothing in human images: a parsing-pose integrated approach. In MCCSIS 2018 - Multi Conference on Computer Science and Information Systems; Proceedings of the International Conferences on Interfaces and Human Computer Interaction 2018, Game and Entertainment Technologies 2018 and Computer Graphics, Visualization, Computer Vision and Image Processing 2018, pp. 205-213 (2018)
[23] Xiao, T., Xu, Y., Yang, K., Zhang, J., Peng, Y., Zhang, Z.: The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 842-850 (2015). https://doi.org/10.1109/CVPR.2015.7298685
[24] Lin, T.-Y., RoyChowdhury, A., Maji, S.: Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, pp. 1449-1457 (2015). https://doi.org/10.1109/ICCV.2015.170
[25] Fu, J., Zheng, H., Mei, T.: Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4438-4446 (2017). https://doi.org/10.1109/CVPR.2017.476
[26] Zheng, H., Fu, J., Mei, T., Luo, J.: Learning multi-attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE International Conference on Computer Vision, pp. 5209-5217 (2017). https://doi.org/10.1109/ICCV.2017.557
[27] Devlin, J.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018). https://doi.org/10.48550/arXiv.1810.04805
[28] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748-8763 (2021)
[29] Gao, D., Jin, L., Chen, B., Qiu, M., Li, P., Wei, Y., Hu, Y., Wang, H.: FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2251-2260 (2020). https://doi.org/10.1145/3397271.3401430
[30] Zhuge, M., Gao, D., Fan, D.-P., Jin, L., Chen, B., Zhou, H., Qiu, M., Shao, L.: Kaleido-bert: Vision-language pre-training on fashion domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12647-12657 (2021). https://doi.org/10.1109/CVPR46437.2021.01246
[31] Ma, H., Zhao, H., Lin, Z., Kale, A., Wang, Z., Yu, T., Gu, J., Choudhary, S., Xie, X.: Ei-clip: Entity-aware interventional contrastive learning for e-commerce crossmodal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18051-18061 (2022). https://doi.org/10.1109/CVPR52688.2022.01752
[32] Han, X., Zhu, X., Yu, L., Zhang, L., Song, Y.-Z., Xiang, T.: Fame-vil: Multi-tasking vision-language model for heterogeneous fashion tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2669-2680 (2023). https://doi.org/10.1109/CVPR52729.2023.00262
[33] Zhang, R., Han, J., Liu, C., Zhou, A., Lu, P., Qiao, Y., Li, H., Gao, P.: LLaMA-adapter: Efficient fine-tuning of large language models with zero-initiated attention. In The Twelfth International Conference on Learning Representations, pp. 1-30 (2024)
[34] Luo, G., Zhou, Y., Ren, T., Chen, S., Sun, X., Ji, R.: Cheap and quick: Efficient vision-language instruction tuning for large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pp. 29615-29627 (2023). https://doi.org/10.5555/3666122.3667410
[35] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp. 24824-24837 (2022). https://doi.org/10.5555/3600270.3602070
[36] Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023). https://doi.org/10.48550/arXiv.2302.00923
[37] Wu, M., Liu, Z., Yan, Y., Li, X., Yu, S., Zeng, Z., Gu, Y., Yu, G.: RankCoT: Refining Knowledge for Retrieval-Augmented Generation through Ranking Chain-of-Thoughts. arXiv preprint arXiv:2502.17888 (2025). https://doi.org/10.48550/arXiv.2502.17888
[38] Niu, T., Joty, S., Liu, Y., Xiong, C., Zhou, Y., Yavuz, S.: Judgerank: Leveraging large language models for reasoning-intensive reranking. arXiv preprint arXiv:2411.00142 (2024). https://doi.org/10.48550/arXiv.2411.00142
[39] Jedidi, N., Chuang, Y.-S., Glass, J., Lin, J.: Don't "Overthink" Passage Reranking: Is Reasoning Truly Necessary? arXiv preprint arXiv:2505.16886 (2025). https://doi.org/10.48550/arXiv.2505.16886
[40] Papineni, K., Roukos, S., Ward, T., Zhu, W.-J.: Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 311-318 (2002). https://doi.org/10.3115/1073083.1073135
[41] Banerjee, S., Lavie, A.: METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pp. 65-72 (2005). https://doi.org/10.5555/1626355.1626389
[42] Lin, C.-Y.: Rouge: A package for automatic evaluation of summaries. In Annual Meeting of the Association for Computational Linguistics, pp. 74-81 (2004)
[43] Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4566-4575 (2015). https://doi.org/10.1109/CVPR.2015.7299087
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Authors

This work is licensed under a Creative Commons Attribution 4.0 International License.


